
In the mid 90s there was a famous incident where an email administrator at a US University fielded a phone call from a professor who was complaining his department could only send emails 500 miles. The professor explained that whenever they tried to email anyone farther away their emails failed — it sounded like nonsense, but it turned out to actually be happening. To understand why, you need to realise that the speed of light actually has more impact on how the internet works than you may think. In the email case, the timeout for connections was set to about 6 milliseconds – if you do the maths that is about the time it takes for light to travel 500 miles.

We’ll be talking about trucks a lot in this blog post!
The time that it takes for a network connection to open across a distance is called latency, and it turns out that latency has a lot to answer for. Latency is one of the main issues that affects the speed of the web, and was one of the primary drivers for why Google started inventing HTTP/2 (it was originally called SPDY when they were working on it, before it became a web standard).
HTTP/2 is now an established standard and is seeing a lot of use across the web, but is still not as widespread as it could be across most site. It is an easy opportunity to improve the speed of your website, but it can be fairly intimidating to try to understand it.
In this post I hope to provide an accessible top-level introduction to HTTP/2, specifically targeted towards SEOs. I do brush over some parts of the technical details and don’t cover all the features of HTTP/2, but my aim here isn’t to give you an exhaustive understanding, but instead to help you understand the important parts in the most accessible way possible.
HTTP 1.1 – The Current Norm
Currently, when request a web page or other resource (such as images, scripts, CSS files etc.), your browser speaks HTTP to a server in order to communicate. The current version is HTTP/1.1, which has been the standard for the last 20 years, with no changes.
Anatomy of a Request
We are not going to drown in the deep technical details of HTTP too much in this post, but we are going to quickly touch on what a request looks like. There are a few bits to a request:
The top line here is saying what sort of request this is (GET is the normal sort of request, POST is the other main one people know of), and what URL the request is for (in this case /anchorman/) and finally which version of HTTP we are using.
The second line is the mandatory ‘host’ header which is a part of all HTTP 1.1 requests, and covers the situation that often a single webserver may be hosting multiple websites and it needs to know which are you are looking for.
Finally there will a variety of other headers, which we are not going to get into. In this case I’ve shown the User Agent header which indicates which sort of device and software (browser) you are using to connect to the website.
HTTP = Trucks!
In order to help explain and understand HTTP and some of the issues, I’m going to draw an analogy between HTTP and … trucks! We are going to imagine that an HTTP request being sent from your browser is a truck that has to drive from your browser over to the server:

A truck represents an HTTP request/response to a server
In this analogy, we can imagine that the road itself is the network connection (TCP/IP, if you want) from your computer to the server:

The road is a network connection – the transport layer for our HTTP Trucks
Then a request is represented by a truck, that is carrying a request in it:

HTTP Trucks carry a request from the browser to the server
The response is the truck coming back with a response, which in this case is our HTML:

HTTP Trucks carry a response back from the server to the browser
“So what is the problem?! This all sounds great, Tom!” – I can hear you all saying. The problem is that in this model, anyone can stare down into the truck trailers and see what they are hauling. Should an HTTP request contain credit card details, personal emails, or anything else sensitive anybody can see your information.

HTTP Trucks aren’t secure – people can peek at them and see what they are carryingWant more advice like this in your inbox? Join the monthly newsletter.
HTTPS
HTTPS was designed to combat the issue of people being able to peek into our trucks and see what they are carrying.
Importantly, HTTPS is essentially identical to HTTP – the trucks and the requests/responses they transport at the same as they were. The response codes and headers are all the same.
The difference all happens at the transport (network) layer, we can imagine it as a over our road:

In HTTPS, requests & responses are the same as HTTP. The road is secured.
In the rest of the article, I’ll imagine we have a tunnel over our road, but won’t show it – it would be boring if we couldn’t see our trucks!
Impact of Latency
So the main problem with this model is related to the top speed of our trucks. In the 500-mile email introductory story we saw that the speed of light can have a very real impact on the workings of the internet.

HTTP Trucks cannot go fast than the speed of light.
HTTP requests and many HTTP responses tend to be quite small. However, our trucks can only travel at the speed of light, and so even these small requests can take time to go back and forth from the user to the website. It is tempting to think this won’t have a noticeable impact on website performance, but it is actually a real problem…
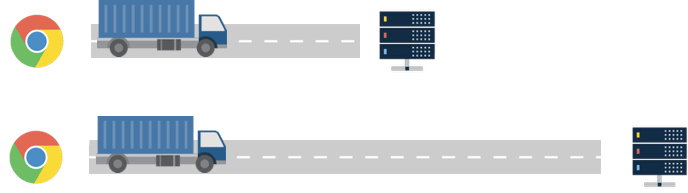
HTTP Trucks travel at a constant speed, so longer roads mean slower responses.
The farther the distance of the network connection between a user’s browser and the web server (the length of our ‘road’) the farther the request and response have to travel, which means they take longer.
Now consider that a typical website is not a single request and response, but is instead a sequence of many requests and responses. Often a response will mean more requests are required – for example, an HTML file probably references images, CSS files and JavaScript files:
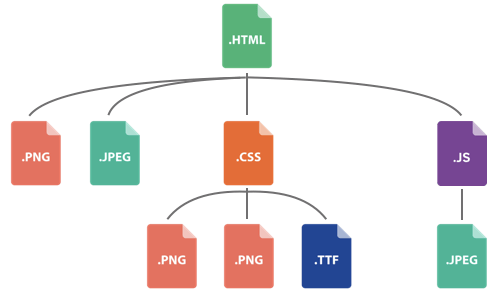
Some of these files then may have further dependencies, and so on. Typically websites may be 50-100 separate requests:
Web pages nowadays often require 50-100 separate HTTP requests.
Let’s look at how that may look for our trucks…
Send a request for a web page:

We send a request to the web server for a page.
Request travels to server:

The truck (request) may take 50ms to drive to the server.
Response travels back to browser:

And then 50ms to drive back with the response (ignoring time to compile the response!).
The browser parses the HTML response and realises there are a number of other files that are needed from the server:

After parsing the HTML, the browser identifies more assets to fetch. More requests to send!
Limit of HTTP/1.1
The problem we now encounter is that there are several more files we need to fetch, but with an HTTP/1.1 connection each road can only handle a single truck at a time. Every HTTP request needs its own TCP (networking) connection, and each truck can only carry one request at a time.

Each truck (request) needs its own road (network connection).
Furthermore, building a new road, or opening a new networking connection also requires a round trip. In our world of trucks we can liken this to needing a stream roller to first lay the road and then add our road markings. This is another whole round trip which adds more latency:

New roads (network connections) require work to open them.

This means another whole round trip to open new connections.
Typically browsers open around 6 simultaneous connections at once:
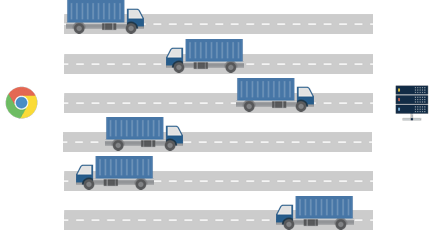
Browsers usually open 6 roads (network connections).
However, if we are looking at 50-100 files needed for a webpage we still end up in the situation where trucks (requests) have to wait their turn. This is called ‘head of line blocking’:
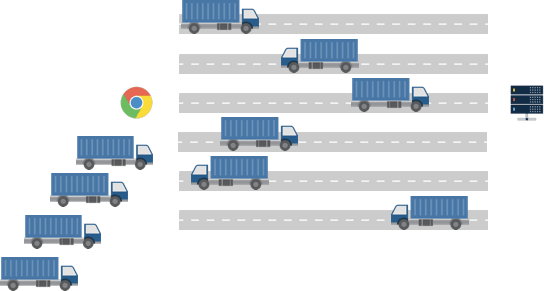
Often trucks (requests) have to wait for a free road (network connection).
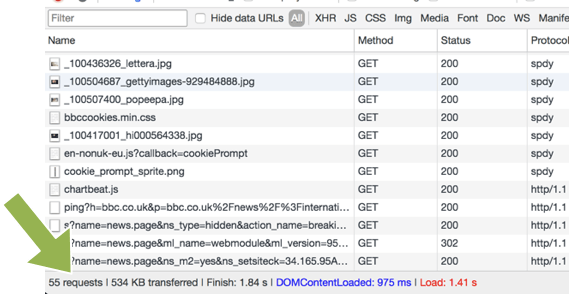
If we look at the waterfall diagram for a page (this example this HTTP/2 site) of a simple page that has a CSS file and lot of images you can see this in action:
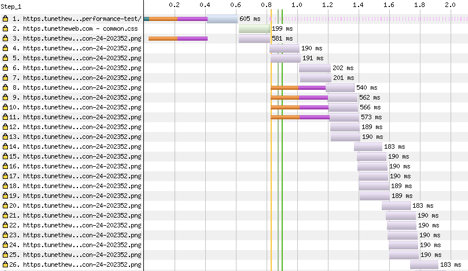
Waterfall diagrams highlight the impact of round trips and latency.
In the diagram above, the orange and purple segments can be thought of as our stream rollers, where new connections are made. You can see initially there is just one connection open (line 1), and another connection being opened. Line 2 then re-uses the first connection and line 3 is the first request over the second connection. When those complete lines 4 & 5 are the next two images.
At this point the browser realises it will need more connections so four more are opened and then we can see requests are going in batches of 6 at a time corresponding with the 6 roads or network connections that are open.